
I'm a Machine Learning Engineer working at eBay. I did my MS in Computer Science and Engineering from SUNY Buffalo. After specializing in software engineering, I thought, "Why not teach machines to learn so I can take longer coffee breaks?" During my studies, I dove into projects involving neural networks and AI—turns out, machines appreciate data even more than I appreciate a good pizza. Previously, I was at Infosys, collaborating with industry veterans and sharpening my technical skills—and my wit. Worked on diverse projects that boosted my logical abilities and out-of-the-box thinking (though sometimes the box was just a cleverly disguised bug ;)
• Programming Languages: Python, Java, SQL, R, Scala, Go, Bash
• Core Frameworks: PyTorch, Keras, TensorFlow, Transformers
• Transformers & NLP: Hugging Face Transformers, spaCy, NLTK
• Cloud & CI/CD: AWS, Terraform, Docker, Kubernetes, Jenkins, Ansible
• Distributed Systems: Spark, Hadoop, Hive, Kafka, Flink, ETL, HDFS
• Data Processing & Analysis: Pandas, NumPy, Dask, Apache Arrow, Matplotlib, Seaborn
more ➜
At eBay, I'm part of some really exciting projects that blend AI with e-commerce—making online shopping smarter every day.
Working on some really cool projects that address the most pressing challenges in the financial industry using Machine Learning and AI.
Experienced Software Engineer proficient in Data Infrastructure contributing to the growth and success of fintech startup Datava.
Worked under the distinguished guidance of the renowned Prof. Dr. Bina Ramamurthy on Distributed Systems at SUNY Research Foundation, New York. Research Topic: A DeFi protocol that operates on a blockchain, enabling automated transactions between cryptocurrency tokens on the Ethereum network (Ropsten) without the need for traditional intermediaries.
As a Software Engineer, I've developed scalable backends in Python and Java, created efficient data pipelines using Spark, AWS, and Jupyter Notebooks, and improved OTA update systems. I've built ETL processes to streamline data ingestion from varied data sources, enhancing data availability for data scientists and ML engineers. I've collaborated with ML engineers to build scalable workflows and automated ETL pipelines using CI/CD tools like Jenkins, Ansible, and Airflow, with Git for version control.
Ideated and created mockups, UML diagrams, and lean business plans for the Internshala Student Portal. Formulated the technical process flow for functionalities and working of online training system.
The Computer Society of India is a non-profit Computer professionals' society and meet to exchange views and information learn and share ideas. The wide spectrum of members is committed to the advancement of theory and practice of Computer Engineering and Technology Systems, Science and Engineering, Information Processing.
Debugger's Club is one of the most prestigious club present in K. K. Wagh College of Engineering Education and Research, Nashik by Department of Computer Engineering.
As a Machine Learning Engineer, I build systems that don't just work—they learn and evolve. With a solid grasp of software, data, and infrastructure, I love turning complex problems into innovative, scalable solutions that actually make a difference.
I love turning data into actionable insights and intelligent systems. Using Python and frameworks like TensorFlow and PyTorch, I build machine learning models that don't just work—they make an impact. My knack for data processing and algorithms helps me create solutions that handle big data without breaking a sweat. Whether it's training models or deploying them into the wild, I enjoy the whole journey of bringing AI projects to life.
Data doesn't organize itself—but that's where I come in. I design and maintain data pipelines using Python, Java, and Spark that keep the information flowing smoothly. Extracting real-time insights from massive datasets is kind of my thing, and it helps businesses make smarter, data-driven choices.
I take pride in simplifying cloud technologies like AWS, Terraform, Docker, and Kubernetes. Whether it's deploying new services or scaling existing ones, I focus on making complex infrastructures accessible and efficient. Automating tasks and optimizing resources? That's where the magic happens.
I enjoy diving into distributed systems like Hadoop, Spark, Hive, and Kafka to process huge amounts of data. Designing efficient and reliable solutions that keep performance up and handle faults gracefully? That's what I do. Big data in a distributed environment doesn't have to be daunting, and I make sure it isn't.
I love making deployments smooth and hassle-free using CI/CD tools like Jenkins, Ansible, and Git. Keeping everything automated and under version control means fewer headaches and more time for the fun stuff. When it comes to data pipelines, Airflow is my trusty sidekick for keeping things efficient and reliable.

Project implemented as a part of Lyft's Prediction challenge on Kaggle
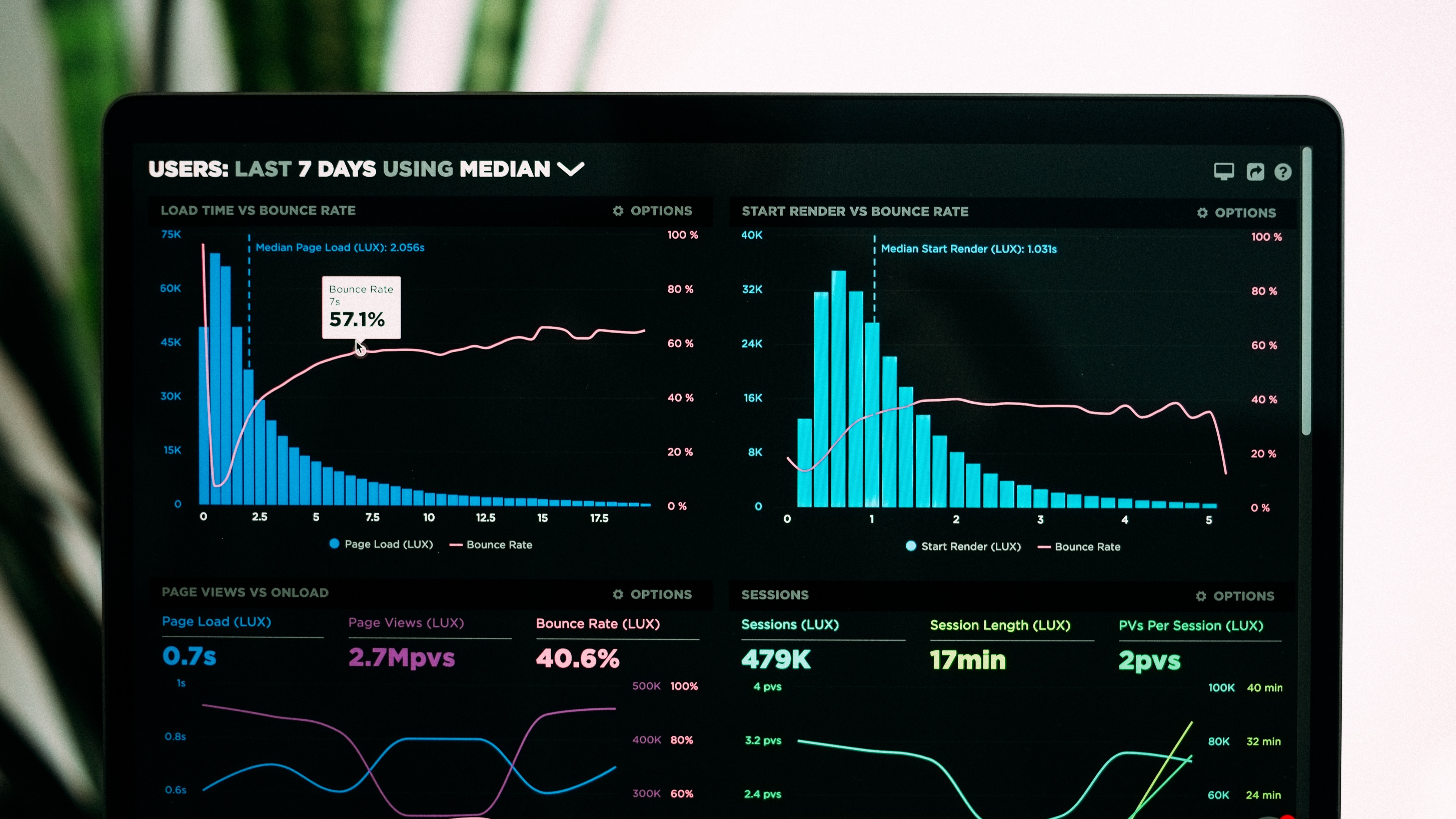
This is a ~1000 line distributed key value store, with support for replication, multiple machines, and multiple drives per machine. Optimized for values between 1MB and 1GB. Inspired by SeaweedFS, but simple. Should scale to billions of files and petabytes of data.

The goal was to develop a system for monitoring and predicting social unrest using natural language processing (NLP) techniques and transformer-based neural network models. The system was designed to analyze ACLED data in real-time and identify patterns and trends that could indicate potential unrest or conflict.
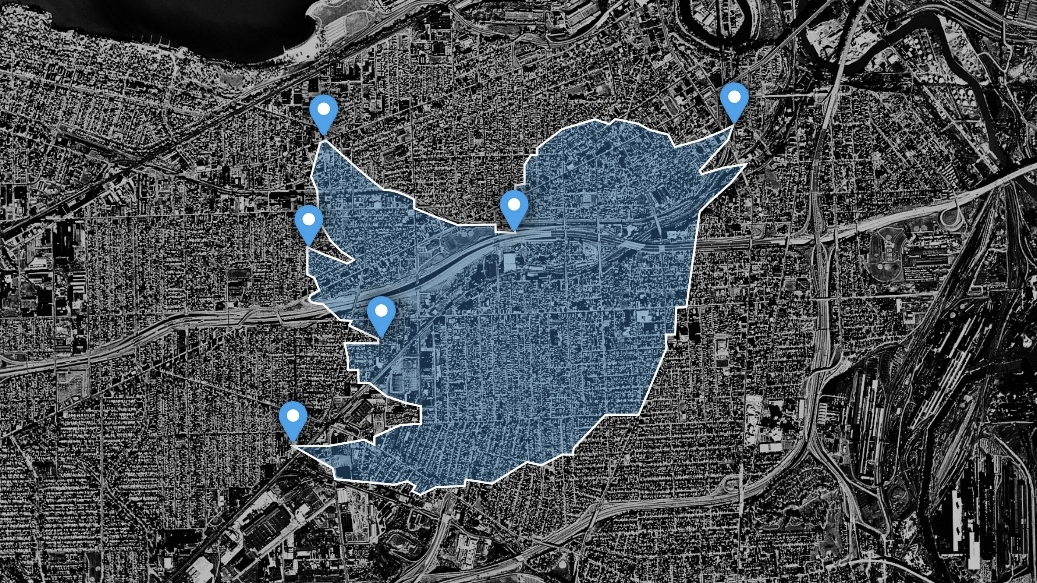
Python package for to understand the geographical context of social media activity

Led development of full-stack digital wallet app, enabling users to connect bank accounts, transactions, pay bills, and earn cashback